Link to original video by CodeEmporium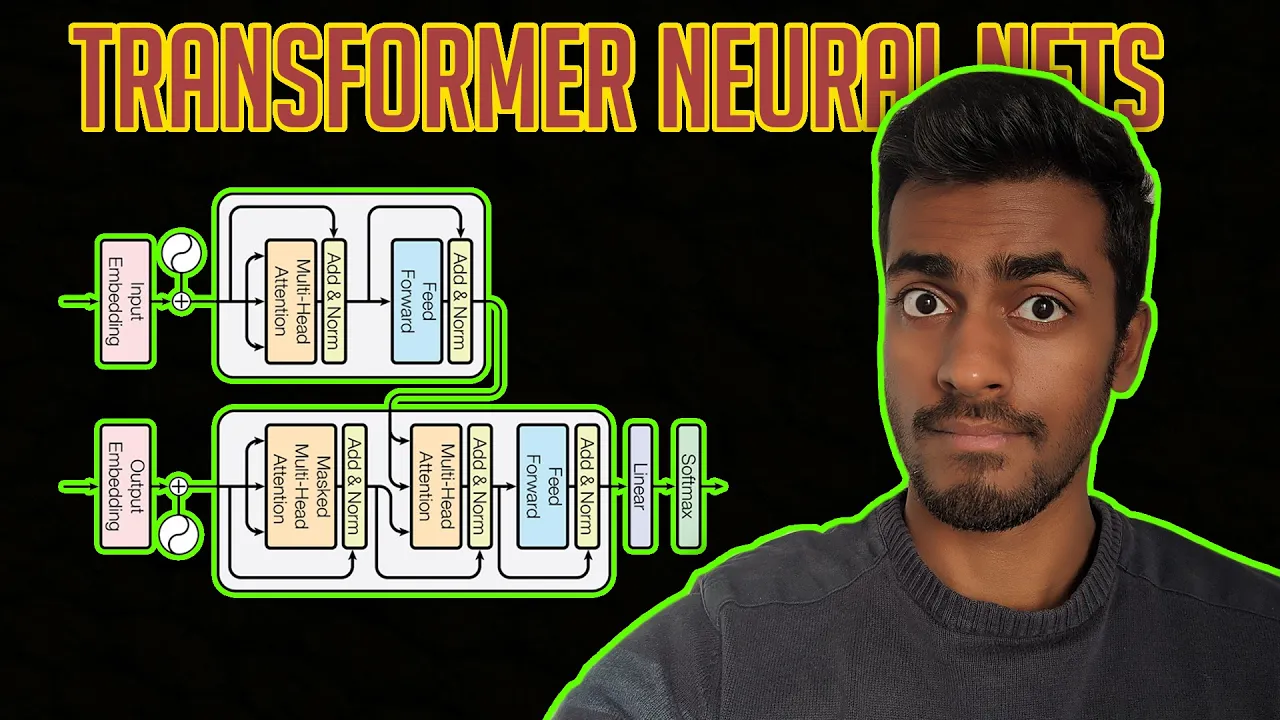
Transformer Neural Networks - EXPLAINED! (Attention is all you need)
Tóm tắt video "Mạng thần kinh Transformer - GIẢI THÍCH! (Attention is all you need)"
Tóm tắt ngắn:
- Video giới thiệu về mạng thần kinh Transformer, một kiến trúc mạng thần kinh mới được giới thiệu vào năm 2017, có khả năng xử lý dữ liệu tuần tự hiệu quả hơn so với các mạng thần kinh tái phát (RNN) truyền thống.
- Transformer sử dụng cơ chế chú ý (attention) để xác định mối quan hệ giữa các từ trong một câu, cho phép mạng học được ngữ cảnh và ý nghĩa của các từ trong câu.
- Transformer đã được ứng dụng thành công trong nhiều lĩnh vực như dịch máy, xử lý ngôn ngữ tự nhiên (NLP), và thậm chí là tạo ra các mô hình ngôn ngữ lớn như BERT.
- Video giải thích chi tiết về kiến trúc của Transformer, bao gồm các thành phần chính như bộ mã hóa (encoder), bộ giải mã (decoder), và cơ chế chú ý nhiều đầu (multi-head attention).
Tóm tắt chi tiết:
Phần 1: Giới thiệu về RNN và các vấn đề của nó
- Video bắt đầu bằng việc giới thiệu về mạng thần kinh tái phát (RNN), một loại mạng thần kinh được sử dụng để xử lý dữ liệu tuần tự.
- RNN có hai loại kiến trúc chính: chuỗi vào vectơ và chuỗi vào chuỗi.
- Tuy nhiên, RNN gặp phải một số vấn đề như tốc độ xử lý chậm, khó xử lý các chuỗi dài, và vấn đề gradient biến mất/bùng nổ.
- Mạng thần kinh LSTM (Long Short-Term Memory) được giới thiệu để giải quyết vấn đề gradient biến mất/bùng nổ, nhưng vẫn còn chậm và phức tạp.
Phần 2: Giới thiệu về Transformer
- Transformer được giới thiệu như một giải pháp thay thế cho RNN, có khả năng xử lý dữ liệu tuần tự hiệu quả hơn.
- Transformer sử dụng kiến trúc bộ mã hóa - bộ giải mã tương tự như RNN, nhưng có thể xử lý dữ liệu song song.
- Ví dụ về dịch máy từ tiếng Anh sang tiếng Pháp được sử dụng để minh họa cách hoạt động của Transformer.
Phần 3: Giải thích chi tiết về kiến trúc Transformer
- Video giải thích chi tiết về các thành phần chính của Transformer:
- Bộ mã hóa (Encoder): Nhận đầu vào là một câu tiếng Anh, chuyển đổi thành các vectơ nhúng, thêm mã hóa vị trí để nắm bắt ngữ cảnh, và sau đó xử lý thông qua các lớp chú ý nhiều đầu và lớp chuyển tiếp nguồn cấp dữ liệu.
- Bộ giải mã (Decoder): Nhận đầu vào là một câu tiếng Pháp, chuyển đổi thành các vectơ nhúng, thêm mã hóa vị trí, và sau đó xử lý thông qua các lớp chú ý bị che giấu, lớp chú ý của bộ giải mã - bộ mã hóa, và lớp chuyển tiếp nguồn cấp dữ liệu.
- Video giải thích chi tiết về cơ chế chú ý nhiều đầu (multi-head attention):
- Chú ý nhiều đầu cho phép mạng học được nhiều mối quan hệ khác nhau giữa các từ trong một câu.
- Các vectơ chú ý được tính toán bằng cách sử dụng các ma trận trọng số Q, K, và V.
- Chuẩn hóa bản vá (layer normalization) được sử dụng để cải thiện tốc độ học tập và ổn định mạng.
Phần 4: Ứng dụng và ý nghĩa của Transformer
- Transformer đã được ứng dụng thành công trong nhiều lĩnh vực như dịch máy, xử lý ngôn ngữ tự nhiên (NLP), và thậm chí là tạo ra các mô hình ngôn ngữ lớn như BERT.
- Transformer đã thay thế phần lớn các mạng LSTM trong các tác vụ xử lý ngôn ngữ tự nhiên.
- Video đề cập đến một bài báo khác về sự chú ý lan tỏa (pervasive attention), có thể hiệu quả hơn Transformer trong một số trường hợp.
Kết luận:
- Video cung cấp một cái nhìn tổng quan về mạng thần kinh Transformer, giải thích chi tiết về kiến trúc và cách hoạt động của nó.
- Transformer là một kiến trúc mạng thần kinh mạnh mẽ, có khả năng xử lý dữ liệu tuần tự hiệu quả hơn so với các mạng thần kinh tái phát truyền thống.
- Transformer đã được ứng dụng thành công trong nhiều lĩnh vực và có tiềm năng lớn để phát triển trong tương lai.